충북대학교 공동훈련센터 IoT기반 스마트 솔루션 개발자 양성과정이
어느덧 3주차가 끝났다
곽내정 교수님과 시작한 약 2주간의 교육을 통해 끝이 나고
C 에 대해 맛보기를 시작했을 무렵 끝난다는 느낌이 들었다
C는 파이썬과 비교가 되는 점도 많았고 비슷한 점도 많았다
어떤 부분에선 편하고 더 프로그래밍 하는 느낌이 들어 멋졌고
어떤 부분에선 이렇게 편한걸 왜 이렇게 쓰고있나 하는 느낌도 들었다
어찌저찌 마지막 곽내정 교수님의 수업은
머신러닝에 대한 기초적인 환경 세팅과 주피터 노트북을 통한 갖가지 모델들을 활용해 보았는데
이 점을 요약해보고자 한다
📋 기초 환경 세팅
우선 머신러닝을 위해선 파이썬을 이용해야 하고
파이썬에서 실행되는 갖가지 라이브러리를 설치해주어야 한다
그를 위해선 아나콘다의 설치가 필요하다
(맥에서 활용할땐 아나콘다가 무거워 보이기도 하고 경로가 혼잡해지기도 해서 쓰기 싫었다
아마 내 기억으론 venv로 그냥 가상환경 폴더 만들고 안에서 돌렸던듯?
가상환경 만들때 말고는 아나콘다의 활용을 많이 해본편은 아니라서
만일 이 부분만 필요하다면 추후 아나콘다의 사용은 안해도 되는 걸로 스스로 판단이 된다)
구글 검색으로 아나콘다만 쳐도 나오기도 하고
아래 링크를 통해 들어갈 수도 있다
https://www.anaconda.com/products/distribution
Anaconda | Anaconda Distribution
Anaconda's open-source Distribution is the easiest way to perform Python/R data science and machine learning on a single machine.
www.anaconda.com
📋 환경변수 경로 세팅
간혹 경로 세팅이 잘못되어 에디터마다 다른 버전의 파이썬 혹은
파이썬을 발견하지 못하는 경우들이 있다
아나콘다의 경우 위와같은 세팅으로 설치를 한 후 실행하면
문제없이 진행이 되지만
만일 파이썬을 찾을 수 없다거나 경로 지정이 안되었다는 오류를 발견한다면
아래 링크를 참조하여 세팅하고
기본적인 가상환경 구성까지 따라해보자
https://mealhouse.tistory.com/7
Tensorflow 환경 설정 및 설치 하기(Windows)
ⓐ Tensorflow 구동을 위한 가상환경 설치 및 환경 설정을 진행하는 단계 기록 및 공유 ⓑ Windows / Mac 두 가지 OS 환경 설치 과정 ⓒ 오류 및 필자가 경험한 상황 공유 * python 이 기본적으로 설치되어
mealhouse.tistory.com
가상환경 구축이 끝났다면
데이터 분석과 모델 생성을 위해 주피터 노트북을 실행해야 한다
위 링크를 참조하면 다음과 같은 라이브러리 설치를 진행하였을 것이다
pip install ipykernelpython -m ipykernel install --user --name 가상환경명 --display-name "가상환경명"conda install tensorflow==버전 : (내가 활용하는 파이썬 버전과 호환되는 tensorflow 버전)
pip install jupyter
이중 ipykernel 과 tensorflow 는 다음시간에 진행해보는것으로 하고
우선적으로 jupyter 만 설치 후 가동시킨다
아나콘다 가상환경 접속 후 jupyter notebook 명령어를 쳐준다

conda env list
conda info --envs
명령어를 쳐보면 자신이 보유하고 있는 가상환경의 위치와 이름을 보여준다
내가 생성해 둔 가상환경의 이름으로 명령어를 입력한다
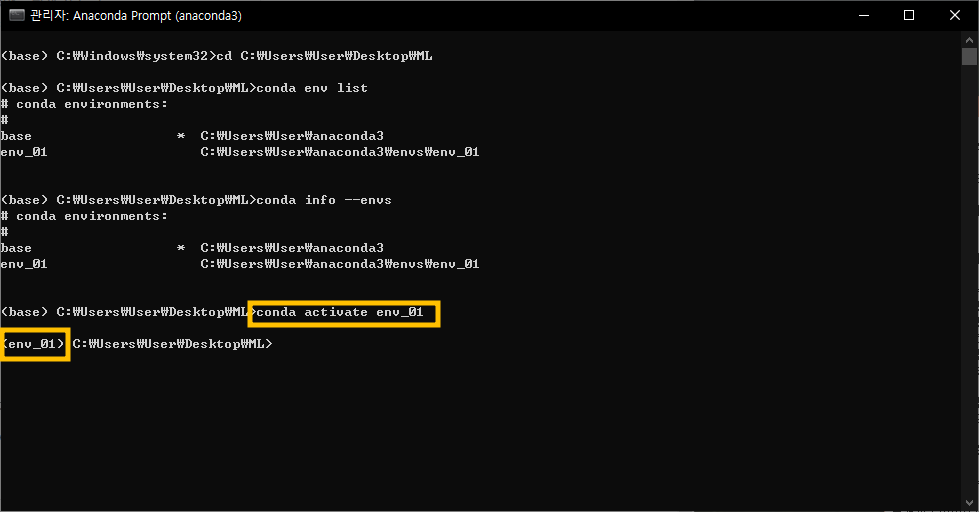
conda activate "가상환경 이름"
명령어를 입력하면 가장 좌측에 보이는 것처럼
해당 가상환경으로의 진입 성공 시 가상환경의 이름으로 바뀐다
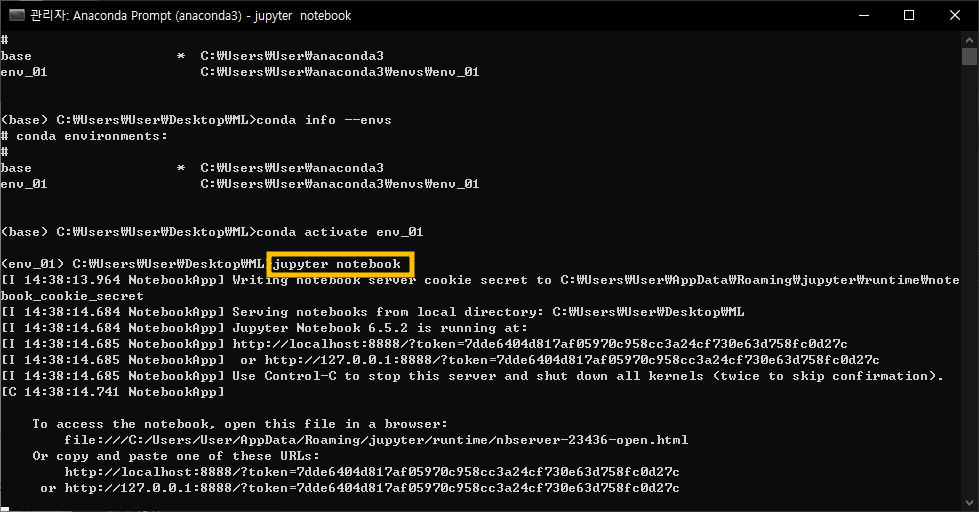
주피터 노트북은 웹 브라우저에서 실행이 되기 때문에
위와 같은 모습을 띄고 있다
++ 주피터 노트북 기본 실행시 가장 기본이 되는 폴더 위치는 C:\Users\User 폴더이다
때문에 이곳에서 실행할 경우 굉장히 난잡한 형태로 파일들이 위치될 수 있고
정리하기 버거웠던 것이 지난번의 경험인데,
이를 해결하기 위해선 내가 원하는 위치에 폴더를 생성하고
가상환경 진입 전, cd 명령어를 통해 해당 폴더의 위치로 진입 후
가상환경 진입 -> 주피터노트북 실행
의 단계를 거치면 깔끔한 형태에서 파일 생성을 시작할 수 있다
📋 주피터 노트북 활용
머신러닝을 진행해보기 전 가장 기본적인 회귀 분석이나
기타 이론적인 부분에 있어선 생략한다
다만, 이번 충북대학교 공동훈련센터 IoT기반 스마트 솔루션 개발자 양성과정 중
배우고 진행했던 코드를 분석해보며 어떤 뜻인지 이해해보자
전체 코드를 먼저 띄우고
한 줄씩 코드 분석을 진행해보도록 한다
※ 설치한 라이브러리
numpy scipy matplotlib spyder pandas seaborn scikit-learn h5py
라이브러리 설치가 안되어 있다면 프롬프트 창(아나콘다 가상환경)에서
pip install 을 통해 설치해주자
import numpy as np
from sklearn import linear_model
regr = linear_model.LinearRegression()
X = [[163], [179], [166], [169], [171]]
y = [54, 63, 57, 56, 58]
regr.fit(X, y)
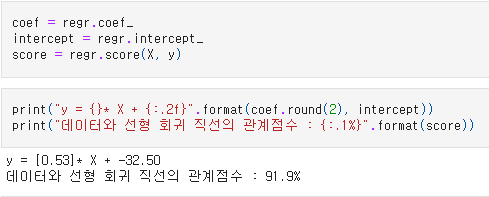
coef = regr.coef_
intercept = regr.intercept_
score = regr.score(X, y)
print("y = {}* X + {:.2f}".format(coef.round(2), intercept))
print("데이터와 선형 회귀 직선의 관계점수 : {:.1%}".format(score))
# ===== 출력결과 =====
y = [0.53]* X + -32.50
데이터와 선형 회귀 직선의 관계점수 : 91.9%
# ====================
import matplotlib.pyplot as plt
plt.scatter(X, y, color = 'blue', marker = 'D')
y_pred = regr.predict(X)
plt.plot(X, y_pred, 'r:')
unseen = [[167]]
result = regr.predict(unseen)
print(f"OO이의 키가 {unseen}cm 이므로 몸무게는 \
{result.round(1)}kg으로 추정됨")
# ===== 출력결과 =====
OO이의 키가 [[167]]cm 이므로 몸무게는 [56.2]kg으로 추정됨
# ====================
regr = linear_model.LinearRegression()
X = [[168, 0], [166, 0], [173, 0], [165, 0], [177, 0], [163, 0],\
[178, 0], [172, 0], [163, 1], [162, 1], [171, 1], [162, 1], \
[164, 1], [162, 1], [158, 1], [173, 1]]
y = [65, 61, 68, 63, 68, 61, 76, 67, 55, 51, 59, 53, 61, 56, 44, 57]
regr.fit(X, y)
print("계수 : ", regr.coef_)
print("절편 : ", regr.intercept_)
print("점수 : ", regr.score(X, y))
print("OO이와 XX의 추정 몸무게 : ", regr.predict([[167, 0], [167, 1]]))
# ===== 출력결과 =====
계수 : [ 0.74803397 -7.23030041]
절편 : -61.227783894306384
점수 : 0.8425933302504424
OO이와 XX의 추정 몸무게 : [63.69388959 56.46358918]
# ====================
x = np.array([1, 4.5, 9, 10, 13])
y = np.array([0, 0.2, 2.5, 5.4, 7.3])
print(x)
print(y)
[ 1. 4.5 9. 10. 13. ]
[0. 0.2 2.5 5.4 7.3]
regr = linear_model.LinearRegression()
x = x[:, np.newaxis]
print(x)
regr.fit(x, y)
print("w = ", regr.coef_.round(2), \
"/ b = ", regr.intercept_.round(2))
# ===== 출력결과 =====
[[ 1. ]
[ 4.5]
[ 9. ]
[10. ]
[13. ]]
w = [0.63] / b = -1.65
# ====================

import numpy as np : numpy 라이브러리를 호출 및 np 라는 이름으로 호출하겠다는 뜻
from sklearn import linear_model : sklearn(사이킷 런) 에서의 linear_model 호출(선형 회귀)
X, y 임의 데이터 생성 및 해당 데이터에 대한 fit 진행
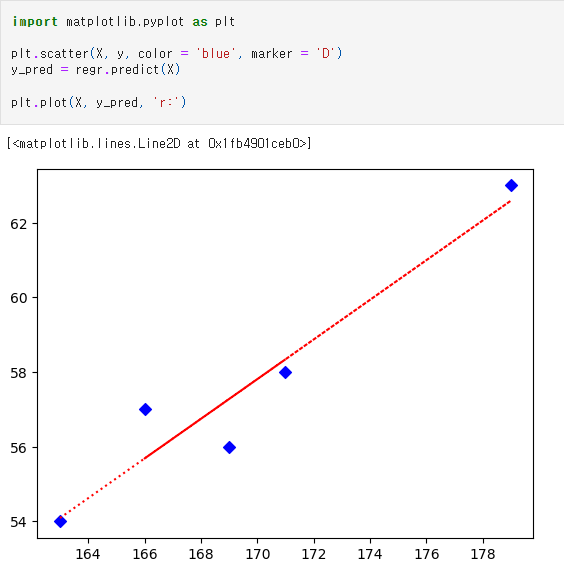
import matplotlib.pyplot as plt : 그래프를 그리기 위한 라이브러리 호출
plt.scatter : matplotlib 에서 산점도를 그리기 위한 함수
plt.plot : 선을 그리기 위한 함수
LinearRegression 모델에 predict(x) 값을 넣어주고 변수로 지정(y_pred)
plt.plot 함수에 기존 X 값과 예측되는 y 값(y_pred)를 그려주면
위와 같은 그림이 나온다
파란색 다이아몬드 그림은 산점도를 그린것
그 이후의 코드들은 위와 같은 형식으로 이루어져 있고,
numpy 배열이 쓰일 뿐 LinearRegression 모델이 쓰이는 것은 같으니
하나하나 천천히 이해하면서 살펴보도록 하자
'Machine Learning' 카테고리의 다른 글
| Tensorflow 환경 설정 및 설치 하기(Windows) (0) | 2022.11.22 |
|---|
